
Avec la profusion des outils de LLM il est intéressant de connaître leurs forces et leurs faiblesses pour savoir lequel utiliser pour un besoin donné et dans un contexte précis.
Aussi je me suis livré à l’exercice en demandant à ChatGPT de répondre au prompt suivant :
« Fais un tableau avec 6 LLM, ChatGPT, Gemini, Mistral, Perplexity, Claude, DeepSeek et 6 éléments de comparaison, le risque d’hallucination, les biais, la suppression des signaux faibles, la compréhension pratique, la fraîcheur des données et la capacité à créer des images à valeur ajoutée (qui répondent précisément au prompt avec créativité, fidélité et pertinence). Et pour chacun de ces éléments une description en 1 ou 2 lignes et un pourcentage associé ».
J’ai retenu 4 LLM américains, ChatGPT, Gemini (d’Alphabet), Perplexity, Claude (d’Anthropic dans lequel Amazon et Alphabet ont investi), 1 français, Mistral et 1 chinois, DeepSeek. J’aurais pu en retenir d’autres comme Llama développé par Meta, Copilot de Microsoft ou encore Grok lié à X.
6 critères me paraissent majeurs dans la comparaison des outils. Ils suivent avec mes explications associées :
- Les hallucinations qui se traduisent par une invention ou une déformation des informations par le LLM ;
- Les biais qui peuvent orienter idéologiquement, culturellement, politiquement, sociologiquement le résultat ;
- La suppression des signaux faibles (et a contrario à surpondérer certains faits) ce qui chasse de fait tout élément qui pourrait être pertinent, une information minoritaire pouvant révéler une rupture ou une tendance future qui émergera ;
- La compréhension pratique sachant qu’outre le fait qu’une IA est dénuée d’émotion, il convient parfois de prompter à plusieurs reprises pour se faire comprendre d’un LLM ;
- La fraîcheur des données en lien avec la connexion à des actualités récentes (à l’origine les connaissances de ChatGPT 3.5 se limitait à septembre 2021, ce qui pouvait être problématique) ;
- La création d’images sachant que Midjourney était une des références ainsi que Firefly d’Abode loin devant DALL-E d’OpenAI avant la dernière version de ChatGPT qui a fait un pas de géant (avec aussi les imitations du style des studios Ghibli et les Starter pack qui donnent lieu à d’abondants posts sur les réseaux sociaux que l’on pourrait appeler autogamification).
Les biais sont nombreux. Le premier biais possible est de demander à un LLM ce qu’il pense de ses concurrents et de lui-même même s’il n’en a pas conscience (quoique). Le second est que certains plus mainstream ont une orientation soit wokiste soit de nature à supprimer tout ce qui pourrait passer comme polémique même si on a des signaux faibles intéressants. C’est le cas de ChatGPT (covid, religion, etc.). La veille, l’intelligence économique et la recherche d’information tant sur les réseaux sociaux, les moteurs de recherche que le Web invisible ont encore de beaux jours devant eux…
Ces résultats représentent une évaluation à l’instant présent laquelle est évolutive en fonction des développements fonctionnels et techniques des outils et de leurs données, entraînements, renforcements, etc.
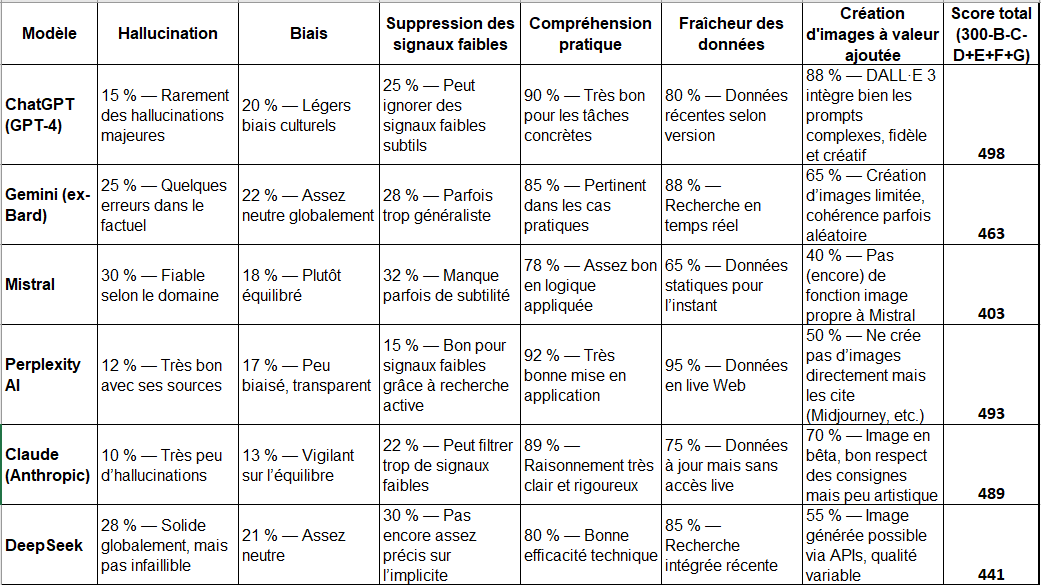
Chaque critère donne lieu à un pourcentage.
Les hallucinations, les biais et la suppression des signaux faibles doivent avoir le score le plus faible possible (entre 0 et 100) pour être synonyme de performance. A contrario, la compréhension pratique, la fraîcheur des données et la capacité à créer des images le plus fort (proche de 100). Pour obtenir un score global pour chacun des LLM, j’applique par conséquent la formule :
300 – score hallucinations – score biais – score suppression des signaux faibles + score compréhension pratique + score fraîcheur des données + score création d’images
Ceci permet d’établir une note de 0 à 600 (on obtient une fourchette de 403 à 498).
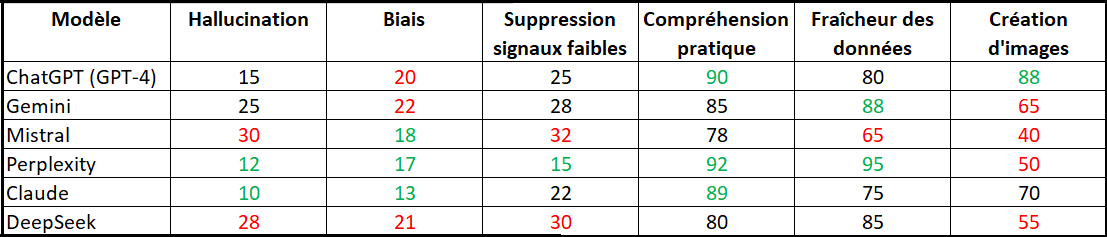
Grâce à la prise en compte des images, ChatGPT l’emporte de peu devant Perplexity et Claude. Du côté de la génération d’images, pour l’heure, ChatGPT tue le match. Sans les prendre en compte, le podium serait différent avec Perplexity devant Claude et ChatGPT.
Notons que ChatGPT n’est pas rentable tout comme Amazon et Facebook qui ont dû attendre 7 et 5 ans pour dégager leurs premiers bénéfices, l’objectif premier étant de devenir le leader et de monétiser ensuite. Là, ce sera plus difficile et on pourrait avoir un comportement de prédation de l’un des GAFAM pour mettre la main sur OpenAI, les relations étant déjà étroites avec Microsoft qui a intégré OpenAI dans son moteur de recherche Bing et a intégré dans sa suite Office Copilot qui est basé sur le modèle GPT-4 d’OpenAI. ChatGPT fait une course à l’innovation laquelle a un coût énergétique et écologique. Avec les prompts pour obtenir des images avec ChatGPT, on génère des pertes (pour le modèle gratuit qui est suffisant mais limité à quelques prompts par jour) et pollution (du fait de la consommation de données titanesques). Dans ce contexte, le modèle Mistral basé sur l’open source ainsi que d’autres LLM sont à suivre. Comme je le dis, nous ne sommes qu’à l’an I de la quatrième ère du numérique, celle de l’IA générative.


 Digital Impacts
Digital Impacts Editions des Cassines
Editions des Cassines Paperblog
Paperblog
1 Commentaire
Exercice amusant, celui qui consiste à demander à ChatGPT de noter tous les LLMs dont lui-même. Mais dans ce cas il eût fallu, AMHA, demander à chacun de comparer tous les autres. Et ce qui est drôle est de voir que ChatGPT avec le même prompt que toi, fait ici à l’instant donne des résultats complètement différents. ce qui est normal car il ne stocke pas ses recherches et ne fournit pas de résultats fiables. Il refait son calcul statistique de zéro à chaque tentative. A noter aussi la tendance à inverser les échelles (certaines croissantes, d’autres décroissantes) ce qui est complètement rédhibitoire (j’ai rétabli les échelles dans mon exemples GPT).
https://1drv.ms/u/s!AquIMRUFGtO_oKFCgxXhNWpDrQpUnw?e=rqnwge
Plus drôle, Perplexity n’a pas l’air d’accord avec toi et ne veut pas noter … PErplexity qu’il considère c
https://www.perplexity.ai/search/fais-un-tableau-avec-6-llm-cha-S8BbQkdsRIOAy2Q3gc6JgA#0
Je me suis arrêté là mais on aurait pu continuer.
On notera également l’absence de lien de partage depuis ChatGPT, qui semble très fier de lui.