
[Article publié sur Agoravox]
|
Le Web au carré est venu compléter la définition restrictive que certains faisaient du Web 2.0. Et alors que le Web 3.0 se définit comme la conjonction du Web sémantique et de l’Internet des objets, je raffine la notion du Web 3.0 en la faisant évolution en Web au cube, étape ultime avant un Web 4.0, bien plus lointain, où se dessinera une singularité technologique : l’intelligence humaine sera supplantée par celle des machines. |

En informatique, les logiciels se distinguent par un numéro de version [1]. Celui-ci indique le contenu fonctionnel et l’interface homme-machine à un instant donné. Le Web, pour sa part, est par essence en évolution permanente (nouveaux entrants, course à l’innovation effrénée, arrivée de standards, nouveaux usages). Ceci a pour corollaire la version bêta perpétuelle, comme le fait Google avec ses produits qui connaissent des raffinements successifs et font fi de toute notion de version. Pourtant l’idée de versions successives applicables aux technologies du web est apparue en octobre 2004 avec le « Web 2.0 » pour illustrer des changements conséquents qui sont de trois ordres :
1. web collaboratif dans lequel l’internaute est à la fois consommacteur et consommauteur et crée des contenus (il publie, commente, modifie via les blogs, wikis, réseaux sociaux, sites participatifs ;
2. évolutions techniques à l’image des flux RSS, des feuilles de style CSS, d’Ajax ;
3. changement du rapport aux données à travers les applications du Web qui se les approprient (par exemple Flickr pour les images, del.icio.us pour les signets, LinkedIn ou Viadeo pour les carnets d’adresses, Gmail pour les méls) même si en même temps une interopérabilité entre les outils est souhaitée à l’image de l’OpenID.
Pour tenir compte des évolutions récentes du Web 2.0 (par exemple évolution dans l’instantanée induite avec des outils comme Twitter) – ou à mon sens amender la définition incomplète donnée en 2004 – Tim O’Reilly l’a fait évoluer avec John Battelle en « Web au carré ». In fine, le Web au carré n’est ni plus ni moins qu’une précision de la définition du Web 2.0 qui dans son acception initiale en 2004 était souvent restreinte notamment dans sa première dimension, Web participatif ou communautaire.
Beaucoup a été publié sur l’après Web 2.0. Ainsi une topographie des discours sur le Web 3.0, notion encore floue, est reproduite en figure 1 [source : Valtech Agency] :
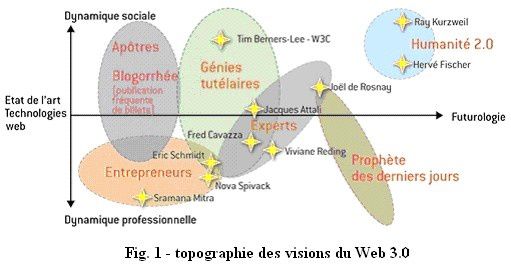
Dans le même ordre d’idée que pour le Web au carré vis-à-vis du Web 2.0 et pour raffiner le concept du Web 3.0, je fais évoluer la notion en le déclinant en « Web au cube » en prenant d’un point de vue terminologique et marketing un peu d’avance.
Les trois dimensions de ce Web au cube seraient :
– la première qui est la définition même que l’on peut admettre aujourd’hui pour le Web 3.0, à savoir la conjonction du web sémantique et de l’Internet des objets. Le Web sémantique repose sur le taguage des données en amont qui consiste à leur attribuer une catégorie d’appartenance (par exemple le mot « licence » peut être attribué à la catégorie « permis » ou « diplôme » selon le contexte d’utilisation du terme) et ce pour une exploitation facile a posteriori et les métadonnées. Concrètement des outils ont été développés pour normaliser le Web sémantique comme RDF – Resource Description Framework -, langage qui définit un cadre général pour la standardisation des métadonnées des ressources sur le Web, des ontologies comme OWL et le langage de requêtes SPARQL pour obtenir des informations à partir de graphes RDF. Des applications ont déjà commencé à arriver, par exemple moteur de recherche sémantique Wolfram Alpha. L’idée du web sémantique est de pouvoir répondre à des interrogations qui seraient formulées en langage naturel par l’utilisateur du type « Qui a gagné le tournoi des 5 nations en 1987 ? » ou « Donnez-moi la meilleure offre compte tenu de mes goûts pour 2 semaines de vacances pour 4 personnes cet été et avec un budget de 2 000 euros ». Pour sa part l’Internet des objets suppose une profusion d’objets communicants au quotidien, de type puces RFID et une kyrielle d’objets avec des adresses IPv6. Ces objets peuvent communiquer entre eux et permettent de créer une « intelligence ambiante ». C’est la définition du Web 3.0 que je donne dans « Web 2.0 et au-delà » ;
– la deuxième, un Web systématiquement ubiquitaire [2] à tout instant, en tout lieu et pour tout type d’action avec des appareils connectés multiples (grâce aux applications basées sur la géolocalisation permises avec par exemple l’explosion du marché des smartphones) et en temps réel avec l’apparition de Web OS (Chrome OS en est l’illustration) et de l’informatique dans les nuages qui reporte le stockage des applications et des données sur des serveurs quelque part sur le Web ;
– la troisième, la généralisation de la 3D et de la réalité augmentée pour l’ensemble des applications.
Ces générations du Web peuvent se résumer dans le tableau figure 2 ci-après :
|
Génération |
Web 1.0 |
Web 2.0 |
Web 3.0 |
Web 4.0 ou X.0 |
|
Année |
1995 (grand décollage d’Internet permis avec la livraison en standard |
2004 (même si des concepts sont apparus avant, par exemple premiers |
2012 (Tim Berners-Lee travaille sur le Web sémantique [3] |
2035 |
|
Définition restrictive |
Web |
Web participatif |
Web sémantique |
Web neuronal |
|
Définition maximaliste (ou enrichie) |
Web dynamique |
Web au carré |
Web au cube |
Web hyperdimensionnel |
|
Commentaires par rapport à la définition maximaliste |
Pages créées avec PHP ou ASP |
Tient compte de l’explosion des usages des réseaux |
Vision maximaliste de l’informatique contemporaine en l’absence |
Web définitif vers lequel on converge avec la « loi de la |
|
Métier induit |
Webmestre |
Community manager |
Technologiste (englobant la fonction d’Information |
Robot generator ? |

 Digital Impacts
Digital Impacts Editions des Cassines
Editions des Cassines Paperblog
Paperblog
Commentaires récents